wegene数据转23andme数据的尝试
本来想试一下dna.land的,结果发型墙内上不了dna.land.........
试了下gedmatch,虽然,去掉了wegene所有的定制位点,但是结果还是和原来一样,有1+%的非洲
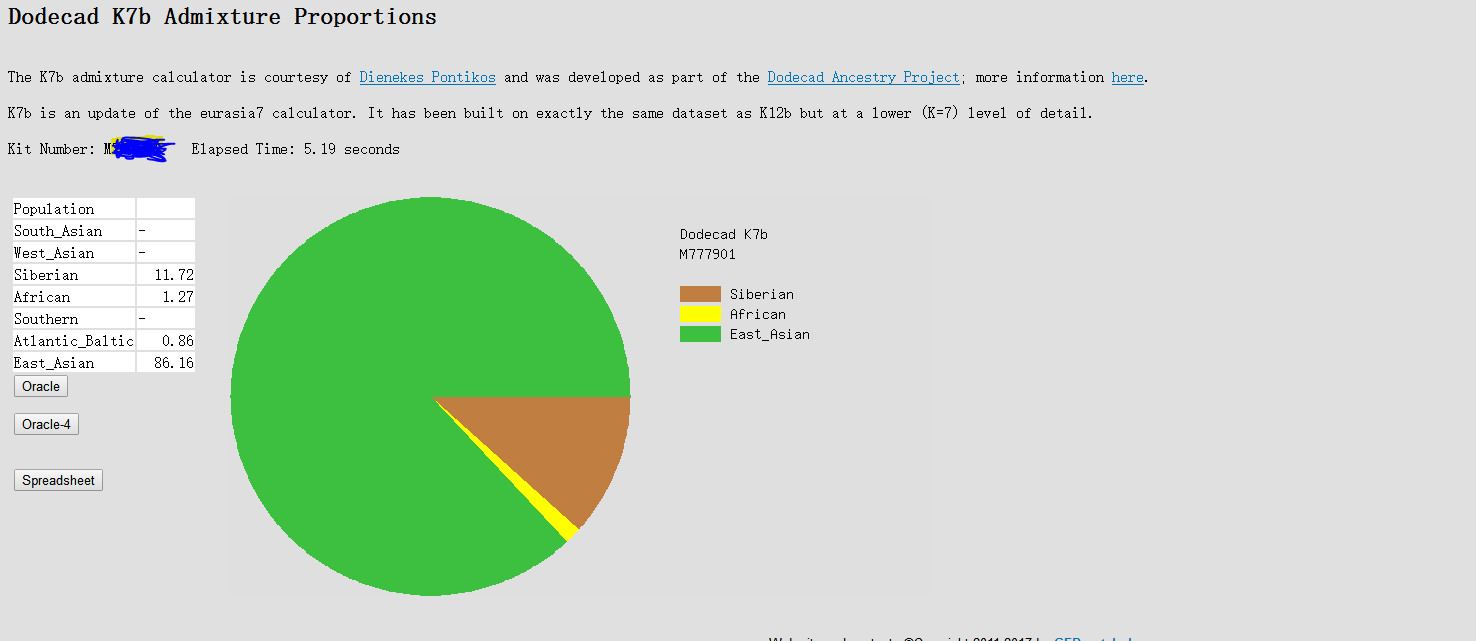
试了下gedmatch,虽然,去掉了wegene所有的定制位点,但是结果还是和原来一样,有1+%的非洲


16 个回复
赞同来自: wls 、蓝星旗 、李璐mlxy 、wanhuatong
把WeGene的原始数据转换成23andme的数据,要解决的问题:
1. 23andme的数据是有5个版本的,从V1到V5。V5是刚刚出来,很多第三方也不支持,V4用了很多年,用得比较多。现在建议以V4为转化目标。
2. 修改rawdata的头部注释信息。很多第三方应用都会验证原始数据txt文件头部的注释信息,这个肯定要改成跟23andme一样的。
3. 修改数据中的SNP列表。WeGene跟23andme的rawdata是有区别的,把两者重叠的部分全部保留。
4. 剩下的是23andme数据中有,而WeGene数据中没有的位点。这部分有几种处理方法,根据我自己的看法,从易到难罗列一下:
4.1 全部标为未检出:这显然是最简单的,但是会损失很多信息,有些第三方应用也会提示数据的nocall rate太高。
4.2 全部用中国人的高频基因型填充:根据千人基因组项目的SNP frequency信息,把中国人群的高频基因型填充进去。这个方法也可以细化一点,比如根据CHB和CHS对南方和北方的数据做不同的处理。
4.3 先用WeGene原始数据中所有的位点,用千人的Chinese做参考数据集,对23andme多测的那些位点的结果做imputation,把impute中info值比较高的位点的impute结果填充进去,impute效果不好的点用未检出填充。
从合理性来说,4.3是最好的
赞同来自: 种骁楠
赞同来自: 蓝星旗
赞同来自: 费力科思
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
要回复问题请先登录或注册