使用本网站需要启用 JavaScript, 请启用后刷新页面获得更好的体验
登录
注册
首页
个人居家检测
临床应用研究
科研合作项目
合作与服务
社区
纯合片段分析
姓氏祖源
祖源平均脸
基因关系
基因保险助手
原始数据
使用 WeGene 需要启用 Cookies, 请启用后刷新页面获得更好的体验
社区首页
祖源讨论区
讨论详情
宽容的SMYD3基因
祖源分析
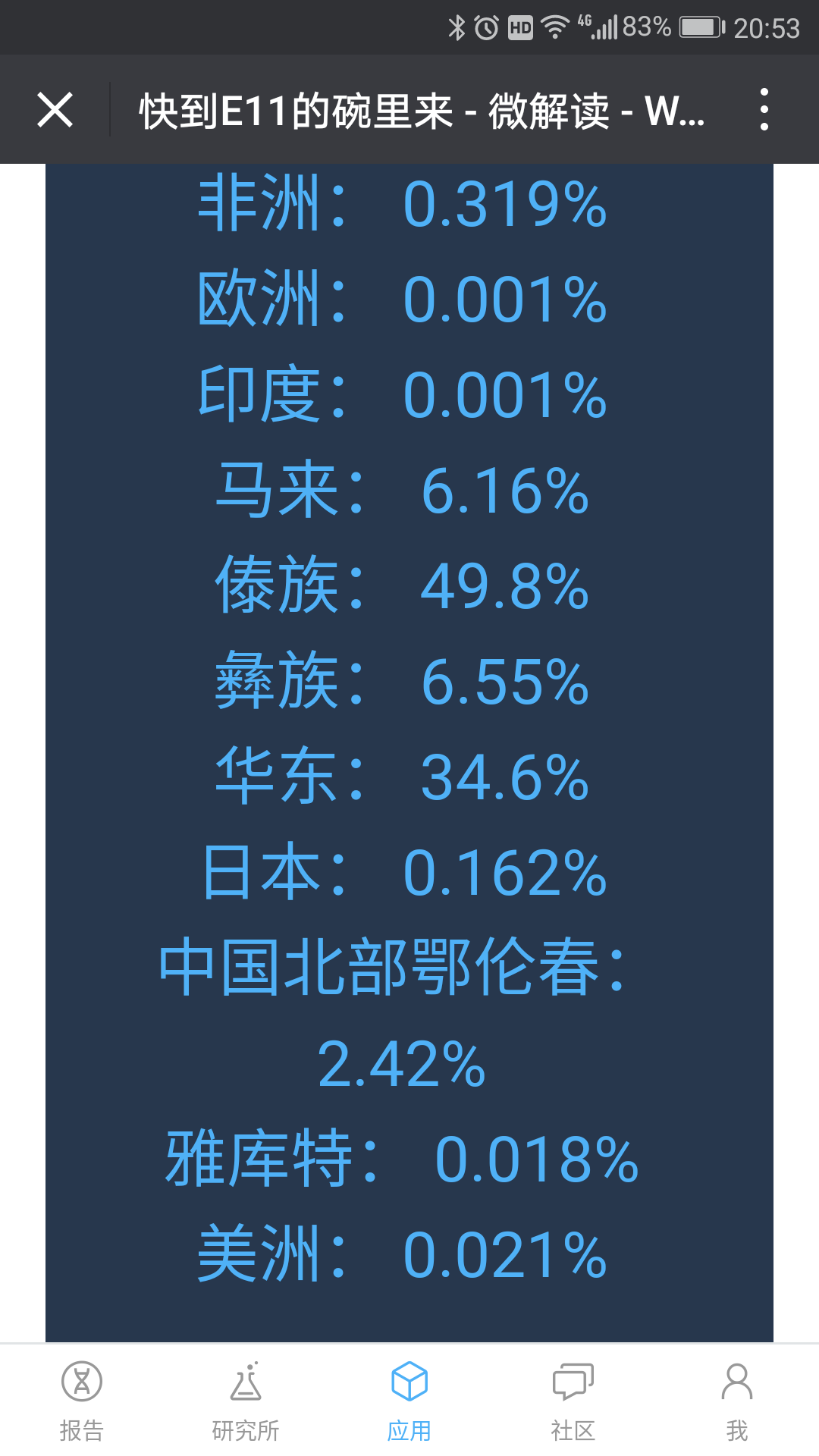
为什么这些祖源差这么大呀
2017-11-19 • IP属地中国
与内容相关的链接
提交
按热门排序
按默认排序
8 个回复
\小阮子/
-
酒不好喝
祖籍那里的?
愉快的NTRK2基因
广西人?
宽容的SMYD3基因
广东的
zkd344596716
粤西的吧a
豪气的FSTL5基因
楼主是粤西哪里人?
宽容的SMYD3基因
肇庆人哈哈哈
zhengqiang
-
勤奋学习
不同的计算器,所用参考民族样本的不一致导致有很大的偏差。建议参考wegene正式提供的为依据去了解其他计算器的差别。
祖源的计算一般是这样的,
A,有1,2,3三种参考族群数据,然后把用户的数据和这1,2,3三种参考族群数据比较相似度,最后得到1,30%,2,40%,3,30%这样的比例结果。
所以当
B,有a,b,c,d,e五种参考数据的时候,同样的一个用户数据和这五种参考数据比较相似度,就会得到a,10%,b,20%,c,30%,d,10%,e.30%这样的结果。。
宽容的SMYD3基因
母系
要回复问题请先
登录
或
注册
发起讨论
祖源分析
4028 个讨论





8 个回复
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
祖源的计算一般是这样的,
A,有1,2,3三种参考族群数据,然后把用户的数据和这1,2,3三种参考族群数据比较相似度,最后得到1,30%,2,40%,3,30%这样的比例结果。
所以当
B,有a,b,c,d,e五种参考数据的时候,同样的一个用户数据和这五种参考数据比较相似度,就会得到a,10%,b,20%,c,30%,d,10%,e.30%这样的结果。。
赞同来自:
赞同来自:
要回复问题请先登录或注册