我祖源怎么就和西藏最相似了呢?
祖源相似性项目开放了这么久,应该采集了足够多的数据了吧。我一浙江人,怎么还是显示我和西藏人祖源最相似呢?
点开看具体的祖源细分,这一点都不像啊,怎么就算出来我和西藏人相似指数达到80%多了呢?
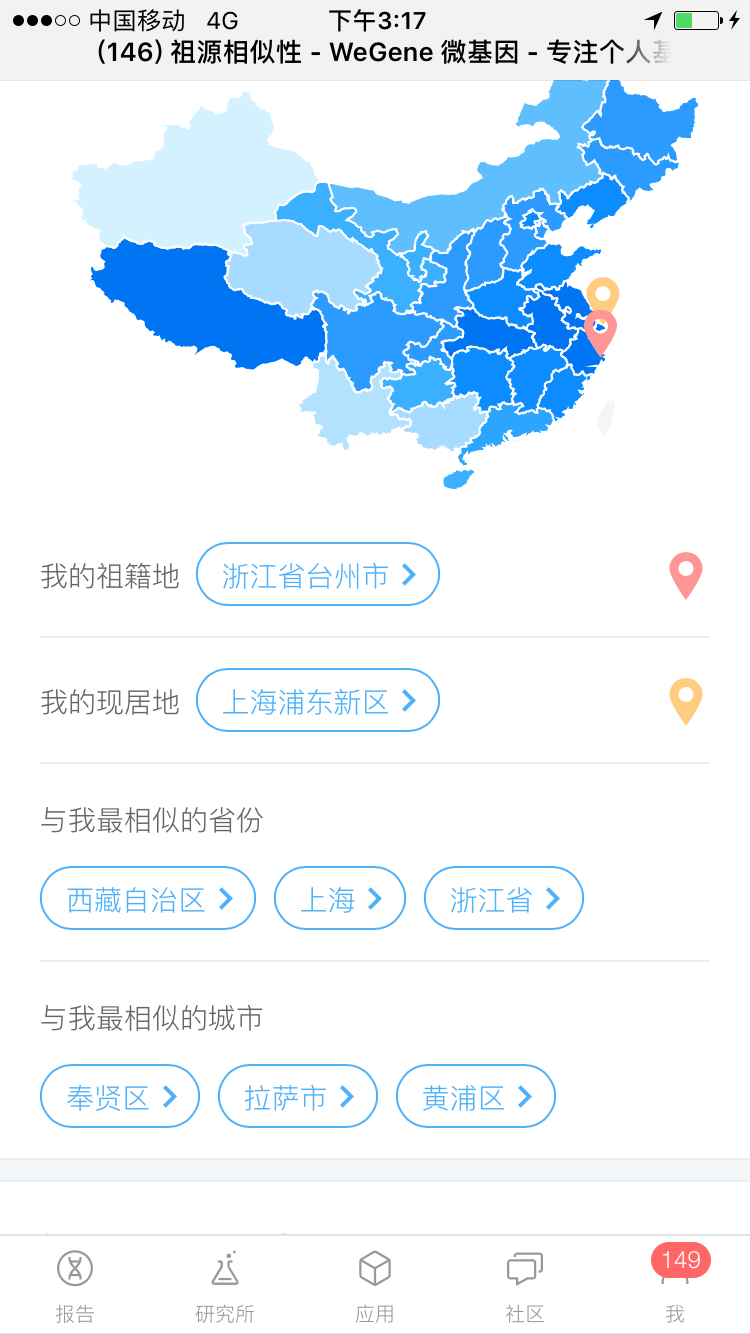


点开看具体的祖源细分,这一点都不像啊,怎么就算出来我和西藏人相似指数达到80%多了呢?


11 个回复
赞同来自: vkrx 、WeChat_FCEAE1
赞同来自: [已注销]
赞同来自:
赞同来自:
遥远的藏羌汉同源部落后人
赞同来自:
赞同来自:
赞同来自:
赞同来自:
记得以前看过关于民意测验的文章,在设计合理的调查中,如果采样真正均匀科学,采样500到1000个就基本能精确的涵盖很大规模的人群,误差很小。不知道他们的数据库里有多少样本,不过就算他们的样本足够多,也肯定不会均匀分布,测试的主要是教育程度高的年轻人。
赞同来自:
赞同来自:
赞同来自:
要回复问题请先登录或注册